加密算法需要的key都是一个byte数组,一般是通过KeyGenerator等类随机生成的。对于我们来说,byte数组是不便于记忆的,因此我们一般是将key导出到一个文件中,在使用的时候再从文件中导入。然而,在某些情况下,我们可能希望从键盘输入一个passphrase,并且使用这个passphrase对数据进行加密。
安全和方便
使用用户输入的密码进行加密,从用户使用角度上非常方便。因为不需要去记忆或者寻找介质保存一段难以理解Key信息。鱼和熊掌不能兼得。在得到了方便的同时,我们损失了安全性。
设想一下,SunJCE提供的DES算法要求的key是56bits,56bits的key一共有256种可能性,也就是72057594037927936种可能性。换句话说,如果使用暴力破解(一个一个实验),最坏的情况下需要72057594037927936次尝试。
现在我们换成使用用户输入的字符作为key。ASCII码能够表示128个字符,其中可以通过键盘输入的只有95个。让我们想得极端一些,用户输入了6个字符的passphrase。也就是说passphrase一共有956种可能性,也就是735091890625种可能。看到了把,这比使用56bit的DESKey减少了将近10万倍。
暴力破解
下面我们来看尝试实际破解一个使用passphrase进行加密的数据。
下面的加密数据是这样得到的:
- 通过键盘输入一个长度为4的Passphrase
- 将Passphrase使用SHA-256进行Hash运算,得到长度为32的Byte数组
- 利用这个Byte数组构造AES算法的Secret Key
- 使用Secret Key利用AES/ECB/PKCS5Padding算法对一段文字的UTF-8编码进行加密
- 加密结果使用Base64编码输出
Base64的输出结果是:
93Gx5o5W6VVuOxQaMn/QgQ==
对于原始数据的SHA-256消息摘要是:
FDF6DDC44BCF8B03D1B0097E09DB36B3A729A21E65BB22539D38B5B00EA96B35
我们不妨尝试写程序暴力破解出使用的Passphrase和解密数据。此处提醒一下,可以通过对比原始数据的消息摘要来验证是否正确的解密。
暴力破解的源码在这里,运行这个程序,需要输入密文,以及原文的消息摘要。可能需要比较长的时间才能计算出结果,请耐心等待。
如此看来,这样的一个passphrase我们可以很容易的就将其破解。现在让我们来反思一下为什么会被破解呢?主要的原因是可以通过键盘输入的字符太少了,这就导致passphrase的组合太少,而且计算机可以很快的从一个passphrase中计算出它对应的key,所以我们可以使用穷举发来逐一实验,并且在一个相对不长的时间内将密码破解出来。
PBE原理
设想一下,如果我们使用更加复杂的算法将passphrase转换成Key,是否会降低被破解的可能呢?现在的逻辑是我们直接使用了SHA-256将任意一个passphrase转换成256Bits的key。现在我们做一个修改,将passphrase进行1000000次SHA-256运算的结果作为key。这样就可以使生成Key的时间增加1000000倍。假设说,利用这个算法,将一个passphrase转换为Key需要3秒钟。那么4位的passphrase有954=81450625种可能性,将每种可能性转化为Key需要3秒钟,然后我们可以通过计算得出总时间为81450625 * 3 / 3600 / 24 = 2828(天)。这个时间一般来说是可以接受的了,而且我们可以通过增加HASH的次数使生成Key的时间更长。
似乎问题就这样被简单的解决了,但是事实并非如此。如果我们不能发现我们的问题,那么我们的对手会帮助我们发现。虽然我们可以通过增加Hash次数来延长生成Key的时间,但是黑客们可能技高一筹。作为黑客,很可能有一个预先已经生成好的列表了,这个列表中包含了每种passphrase经过1000000次SHA-256之后的结果。这样一来,黑客就可以绕过我们设定好的1000000次HASH,直接利用预先计算好的Hash结果进行破解。
为了避免黑客们使用这种预先计算好的Key列表,我们需要在原本的passphrase中加入Salt——盐。所谓盐,就是在进行Hash计算的时候,在passphrase上附加上一定长度的随机的byte数组。因为这个byte数组的长度和内容都是任意的,所以这就大大降低了黑客有预先计算好的Key列表这种可能性。从而强制意欲不轨的人想要得到每种passphrase对应的key,就必须按照规定好的算法进行1000000或者更多次的Hash运算。
Salt的选取
那么这里有一个问题:我应该如何选取Salt呢?涉及到两方面:
- 内容选取
- 长度选取
对于内容,尽可能是随机的。记住不要使用java.util.Random类来生成随机的Salt,因为java.util.Random是不安全的,可以使用SecureRandom来生成随机的Salt。
对于长度,先给出结论,应该尽可能的长,但是不需要超过Hash算法输出的长度。比如SHA-256输出256Bit的hash结果,因此需要32字节的Salt。原因是这样的:虽然Hash算法能够尽量保证不同的输入产生不同的Hash值,但是只要稍微一想就可以知道,这是不可能的。原因很简单,输入数据的可能性是无穷大的,而输出数据却是固定的长度,可能是256Bit。所以对于不同的输入,肯定有可能得到相同的输出。对于输出是256Bits的Hash算法,最多能够产生2256中不同的Hash值。那么,最理想的情况下,这2256个Hash值恰巧由同一个passphrase+2256种salt计算得出。而2265种salt恰巧就是256Bits所能表示的范围。换句话说,最完美的情况下,这会最大限度的减少黑客拥有预先算好的Key的可能性,如果Salt更长,那么就有可能和另外一个256Bits的Salt的Hash值重复了,所以是没有必要的。那么完美情况下,超出了Hash算法输出长度的Salt可能重复,就更不用说不完美的情况了——Salt用不着超出256Bits,就已经存在重复的了,因此就更加没有必要计算超过Hash输出结果长度的Salt了。
Java中的PBE
Java中提供了两种PBE的实现方式:PBE方式和PBKDF2方式
PBE方式
Key的生成在Cipher内部。即,在使用时,需要把Passphrase, Salt, Iteration Count都传入到Cipher中,Cipher内部会根据这些信息,计算出最终的Key,并且在加密解密时使用。
使用步骤:
- 通过Passpharse构造PBEKeySpec
- 利用SecretKeyFactory将PBEKeySpec转换成PBEKey
- 使用Salt和Iteration Count来构造PBEParameterSpec
- 通过调用Cipher类的init方法将PBEKey和PBEParameterSpec传入Cipher中
- 利用Cipher的doFinal方法对数据进行加密或者解密。
其计算Key的过程在调用Cipher的init方法时进行
下面是一个使用PBE的例子:
public class PBECipher {
private Cipher encryptCipher;
private Cipher decryptCipher;
/**
* 使用MD5算法将Passphrase转换成DES所用的Key
*/
private final static String ALGORITHM = "PBEWithMD5AndDES";
public PBECipher(char[] passphrase, byte[] salt, int iterationCount) {
Key key = generatePBEKey(passphrase);
encryptCipher = generateCipher(Cipher.ENCRYPT_MODE, key, salt, iterationCount);
decryptCipher = generateCipher(Cipher.DECRYPT_MODE, key, salt, iterationCount);
}
private Key generatePBEKey(char[] passphrase) {
try {
/**使用passphrase构造PBEKeySpec*/
PBEKeySpec keySpec = new PBEKeySpec(passphrase);
/**使用SecretKeyFactory将PBEKeySpec转换为PBEKey*/
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance(ALGORITHM);
SecretKey key = keyFactory.generateSecret(keySpec);
return key;
} catch (NoSuchAlgorithmException | InvalidKeySpecException ex) {
throw new RuntimeException(ex);
}
}
private Cipher generateCipher(int opmode, Key key, byte[] salt, int iterationCount) {
try {
/**使用Salt和Iteration Count来构造PBEParameterSpec*/
PBEParameterSpec parameterSpec = new PBEParameterSpec(salt, iterationCount);
Cipher cipher = Cipher.getInstance(ALGORITHM);
/**使用Key和PBEParameterSpec对Cipher进行初始化*/
cipher.init(opmode, key, parameterSpec);
return cipher;
} catch (NoSuchAlgorithmException | NoSuchPaddingException | InvalidAlgorithmParameterException | InvalidKeyException ex) {
throw new RuntimeException(ex);
}
}
public byte[] encrypt(byte[] plainData) {
return transform(encryptCipher, plainData);
}
public byte[] decrypt(byte[] cipherData) {
return transform(decryptCipher, cipherData);
}
private byte[] transform(Cipher cipher, byte[] data) {
try {
byte[] cipherData = cipher.doFinal(data);
return cipherData;
} catch (IllegalBlockSizeException | BadPaddingException ex) {
throw new RuntimeException(ex);
}
}
public static void main(String[] args) throws Exception {
byte[] salt = { -81, 93, -1, -32, -17, -33, -55, -66 };
long start = System.currentTimeMillis();
/**Iteration Count为100000000,因此会进行10000000次Hash运算来计算Key*/
PBECipher cipher = new PBECipher("1qaz2wsxE".toCharArray(), salt, 10000000);
long end = System.currentTimeMillis();
System.out.println("Time elapsed: " + ((end - start)));
String text = "Hello PBE";
byte[] data = text.getBytes("UTF-8");
byte[] cipherData = cipher.encrypt(data);
byte[] plainData = cipher.decrypt(cipherData);
String plainText = new String(plainData, "UTF-8");
System.out.println(plainText);
}
}
运行程序将得到如下输出:
Time elapsed: 9501
Hello PBE
首先我们可以看到解密后的数据和我们加密前的数据是一致的,因此可以证明加密解密的过程是正确的;另外一点需要注意Time elapsed,因为我们设置了Iteration Count为10000000,因此Cipher的init方法的执行时间会怎加,用于进行Key的计算,以此让暴力破解变得不易。
按照我们上面的分析,如果使用MD5将Passphrase转换为Key,因为MD5输出的散列结果是128 Bit(16 Bytes),所以理想的Salt长度是16 Bytes。但是需要注意,在Java的默认实现中,PBE方式要求Salt的长度只能是8 Bytes。这也是为什么不推荐使用PBE方式的原因之一。
Java的默认实现中支持4种加密算法的PBE实现:
- PBEWithMD5AndDES
- PBEWithMD5AndTripleDES
- PBEWithSHA1AndDESede
- PBEWithSHA1AndRC2_40
我们知道Key的计算是在Cipher内部完成的,那么在Cipher内部是如何将Passphrase转换成Key的呢?通过研究PBECipherCore类的源码,我们看到其中的deriveCipherKey方法是这样进行转换的:
- 将Passphrase转换为字节数组
- 把salt附加在passphrase转换的字节数组后面
- 将保存着passphrase和salt的字节数组进行iteration count次MD5运算,最终得到了长度是16 Bytes的结果
- 从16 Bytes的运算结果中取出前8 Bytes,做为DES算法的Key
- 同样,从16 Bytes的运算结果中取出前8 Bytes,做为加密时使用的IV
从这个过程中我们可以看到,Java的默认实现中,PBE方式的IV和Key的计算方式是一样的,因此降低了安全性,这也是不推荐使用PBE方式的另一个原因。
PBKDF2方式
Sun在JDK 1.4中引入了PBKDF2方式,来支持passphrase到Key的转换。和PBE方式不同,PBKDF2方式将Passphrase转换Key的过程从Cipher中分离出来,使之更加具有弹性。利用PBKDF2方式可以将一个passphrase转换成任意长度的key,在得到了Key之后,就可以使用普通的加密算法(DES/AES等算法)对数据进行加密。
使用步骤:
- 使用Passphrase,Salt,Iteration Count来构造PBEKeySpec
- 使用SecretKeyFactory将PBEKeySpec转换成PBKDF2Key
- 调用PBKDF2Key的getEncoded方法获取Encoded Key
- 使用Encoded Key构造SecretKeySpec,即得到SecretKey
- 使用得到的SecretKey对Cipher进行初始化
- 使用Cipher对数据进行加密或者解密
下面是一个PBKDF2的例子:
public class PBKDF2Cipher {
private Cipher encryptCipher;
private Cipher decryptCipher;
public PBKDF2Cipher(char[] passphrase, byte[] salt, int iterationCount, byte[] iv) {
long start = System.currentTimeMillis();
/**将Passphrase, Salt, Iteration转换成Key*/
Key key = generateKey(passphrase, salt, iterationCount);
long end = System.currentTimeMillis();
System.out.println("Time elapsed: " + (end - start));
/**使用得到的SecretKey对Cipher进行初始化*/
encryptCipher = generateCipher(Cipher.ENCRYPT_MODE, key, iv);
decryptCipher = generateCipher(Cipher.DECRYPT_MODE, key, iv);
}
private Key generateKey(char[] passphrase, byte[] salt, int iterationCount) {
try {
/**使用Passphrase,Salt,Iteration Count来构造PBEKeySpec*/
PBEKeySpec keySpec = new PBEKeySpec(passphrase, salt, iterationCount, 256);
/**使用SecretKeyFactory将PBEKeySpec转换成PBKDF2Key*/
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("PBKDF2WithHmacSHA1");
SecretKey tempKey = keyFactory.generateSecret(keySpec);
/**
* 调用PBKDF2Key的getEncoded方法获取Encoded Key
* 使用Encoded Key构造SecretKeySpec,即得到SecretKey
*/
SecretKey key = new SecretKeySpec(tempKey.getEncoded(), "AES");
return key;
} catch (NoSuchAlgorithmException | InvalidKeySpecException ex) {
throw new RuntimeException(ex);
}
}
/**
* 创建Cipher,并且使用key和IV进行初始化
* 此处和正常是使用Cipher没有任何区别
* @param opmode
* @param key
* @param iv
* @return
*/
private Cipher generateCipher(int opmode, Key key, byte[] iv) {
try {
Cipher cipher = Cipher.getInstance("AES/CBC/PKCS5Padding");
IvParameterSpec ivParameterSpec = new IvParameterSpec(iv);
cipher.init(opmode, key, ivParameterSpec);
return cipher;
} catch (NoSuchAlgorithmException | NoSuchPaddingException | InvalidKeyException | InvalidAlgorithmParameterException ex) {
throw new RuntimeException(ex);
}
}
public byte[] encrypt(byte[] plainData) {
return transform(encryptCipher, plainData);
}
public byte[] decrypt(byte[] cipherData) {
return transform(decryptCipher, cipherData);
}
/**
* 使用Cipher对数据进行加密或者解密
* @param cipher 加密或者解密使用的Cipher
* @param data 待加密或者解密的数据
* @return 加密或者解密的结果
*/
private byte[] transform(Cipher cipher, byte[] data) {
try {
byte[] tData = cipher.doFinal(data);
return tData;
} catch (IllegalBlockSizeException | BadPaddingException ex) {
throw new RuntimeException(ex);
}
}
public static void main(String[] args) throws Exception {
byte[] salt = { 125, 26, -86, -29, -79, -11, 10, 51, -29, -24, -128, -95, 0, -16, -95, 52, -90, -54, 63, -19 };
byte[] iv = { 125, -53, 114, 46, -62, 48, -36, 80, -70, 56, -65, -46, 62, 39, -77, -18 };
PBKDF2Cipher cipher = new PBKDF2Cipher("1qaz2wsxE".toCharArray(), salt, 1000000, iv);
String text = "Hello PBKDF2";
byte[] data = text.getBytes("UTF-8");
byte[] cipherData = cipher.encrypt(data);
byte[] plainData = cipher.decrypt(cipherData);
String plainText = new String(plainData, "UTF-8");
System.out.println(plainText);
}
}
运行上面的程序,将得到如下输出:
Time elapsed: 7837
Hello PBKDF2
可以看到正确的解密结果,可以证明加密解密的过程是正确的。另外,我们可以看到在生成Key的时候花费了7837毫秒,这是因为在生成Key的时候进行了1000000次Hash运算。此处可以看到和PBE方式的不同,PBE方式是在初始化Cipher的时候进行Hash运算的,而PBKDF2方式是使用KeyFactory将Passphrase转换成Key的。
那么KeyFactory是如何将PBEKeySpec转换成PBEKey的呢?Java中默认的PBKDF2实现中,使用的是PBKDF2WithHmacSHA1. 正如这个算法的名字,其用于生成Key的Hash算法是HmacSHA1,也就是带有Secret Key的SHA1算法。通过查看PBKDF2KeyImpl的源码,我们可以得到PBKDF2生成Key的详细步骤:
- 使用UTF-8对passphrase进行编码,得到passphrase对应的byte数组
- 把passphrase的byte数组作为Key,初始化HmacSHA1
-
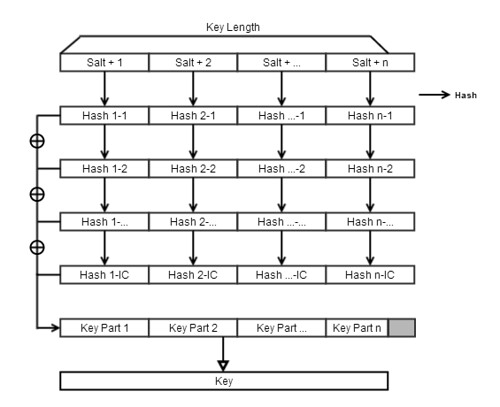
根据需要的Key Length和Hash算法的输出长度来计算需要分成多少个Block来生成Key。以PBKDF2WithHmacSHA1生成AES-256 Key为例,AES-256 Key需要的长度是256 Bits,而HmacSHA1的输出是160 Bits,所以两个Hash结果才能拼成一个AES-256 Key,这样我们就说需要分成两个Block来计算AES-256 Key。
计算公式:
(KeyLength + HashLength - 1) / HashLength。
- 顺次计算每个Block的Hash结果,每个Block的初始值是Salt+序号。比如第一个Block的初始值是Salt+1,以此类推,第二个Block的初始值是Salt+2…
- 使用Hmac计算Block初始值的Hash值,利用得到的Hash值继续使用Hmac进行Hash,一直进行Iteration Count次Hash。
- 将这些Hash结果进行异或,得到当前Block的最终运算结果。
- 继续进行第五步,直到得到所有Block的最终运算结果。
- 将所有的Hash结果组成一个完整的Key,对于最后一次的Hash结果可能需要将尾部截掉。
下图是PBKDF2计算Key的示意图:
为了便于理解,下面是仿造JDK源码,写的一段模拟计算Key的代码:
public class PBKDF2Derivation {
private String hashAlgorithm;
private Mac mac;
public PBKDF2Derivation() {
hashAlgorithm = "HmacSHA1";
try {
mac = Mac.getInstance(hashAlgorithm);
} catch (NoSuchAlgorithmException ex) {
throw new RuntimeException(ex);
}
}
public byte[] deriveKey(char[] password, byte[] salt, int iterCount, int keyLengthInBit) {
byte[] encodedPassword = getPassword(password);
try {
mac.init(new SecretKeySpec(encodedPassword, "HmacSHA1"));
} catch (InvalidKeyException ex) {
throw new RuntimeException(ex);
}
if (keyLengthInBit % 8 != 0) {
throw new IllegalArgumentException("Key Length must be multiple of 8");
}
int keyLengthInByte = keyLengthInBit / 8;
byte[] keyData = new byte[keyLengthInByte];
int macLength = mac.getMacLength();
int blockCount = (keyLengthInByte + macLength - 1) / macLength;
int lastHashLength = keyLengthInByte - macLength * (blockCount - 1);
for (int i = 1; i <= blockCount; i++) {
mac.update(salt);
mac.update(convertInt2Bytes(i));
byte[] hash = mac.doFinal();
byte[] newHash = hash;
for (int j = 1; j < iterCount; j++) {
newHash = mac.doFinal(newHash);
for (int k = 0; k < hash.length; k++) {
hash[k] ^= newHash[k];
}
}
if (i < blockCount) {
System.arraycopy(hash, 0, keyData, (i - 1) * macLength, hash.length);
} else {
System.arraycopy(hash, 0, keyData, (i - 1) * macLength, lastHashLength);
}
}
return keyData;
}
private byte[] getPassword(char[] password) {
Charset utf8 = Charset.forName("UTF-8");
ByteBuffer encodedPasswordBuffer = utf8.encode(CharBuffer.wrap(password));
byte[] encodedPassword = encodedPasswordBuffer.array();
return encodedPassword;
}
private byte[] convertInt2Bytes(int i) {
byte[] bytes = new byte[4];
bytes[3] = (byte) i;
bytes[2] = (byte) ((i >> 8) & 0xff);
bytes[1] = (byte) ((i >> 16) & 0xff);
bytes[0] = (byte) ((i >> 24) & 0xff);
return bytes;
}
}
PBE方式 vs. PBKDF2方式
相比PBE方式,更加推荐使用PBKDF2方式:
- Java的默认实现中PBE方式不能设置Salt的长度,只能是规定的16 Bytes,而PBKDF2方式却可以设置任意长度的Salt。
- PBE方式的IV和Key都是通过Passphrase计算出来的,而且不能单独设置IV。PBKDF2方式却可以对IV完全独立设置,提高了安全性。
- PBKDF2方式将Key的计算完全隔离出来,更加具有弹性。









